🚀 Intro
I made this because I was bored. Actually, that's not the full truth. I was looking to build something new and fun because I was feeling some burnout.
I was inspired by the YouTube video These Fake Animated Stories Have Gone Too Far by Jarvis Johnson. In his commentary video, Johnson explored the eye-grabbing and "clickbait" titles of the videos made by certain animated story channels. As well, he made a website where you can generate a random animated story title. He detailed how he utilized a language-learning model called the Markov chain.
🏆 Goals
Initially, my goal was to learn about the Markov chain model because it felt like the closest artificial intelligence I can construct by myself without having access to tons of data.
After understanding how the stochastic model worked, I then changed my goal to replicate Johnson's website by making a sentence-generator site of my own.
⏳ Development
The Markov chain is a probabilistic model that transitions through a sequence of events based on defined probabilistic rules. The probability of a future event is determined only by the current event, not on past events. Hence, the future is independent of all past events which is why it appears random.
For simplicity, I will refer to "Markov chain" as Markov. Throughout your reading journey, I will include buttons to reveal some supplementary information. These only provide additional information and are not mandatory - but I highly recommend reading them! For example, let's briefly go over how Markov works in practice. Consider the sentence: the quick brown fox jumps over the lazy dog
The word the is followed by the words quick and lazy, each one time. So, if the current event is the, there is an equal 50% chance that the next event will be either quick or lazy. The remaining words have a 100% chance of leading directly to the word that follows in that sentence. Therefore, generated results may include, but are not limited to, the following lines of text:
the quick brown fox jumps over the lazy dogthe lazy dogthe quick brown fox jumps over the quick brown fox jumps over the lazy dog
You can imagine how unlucky (or lucky...?) one might be to keep generating "the quick brown fox jumps over" over and over again. This is possible because, when we land on the, there is a 50% chance to proceed with quick, followed by a 100% chance to proceed with brown, then a 100% chance to proceed with fox, etc. Remember, the future is independent of the past, so programs need to know when to stop finding the next event.
First, I used the Java programming language to help my Markov learning. I used a HashMap data structure to build a "dictionary" for the events and for efficient data retrieval. Each valid String event was mapped to a custom Node object, which contained information about its proceeding event(s).
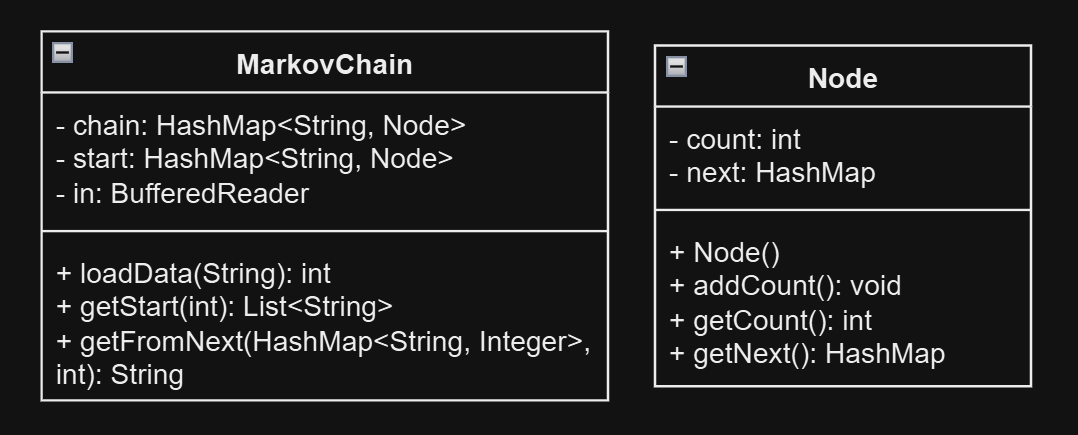
MarkovChain and NodeTo obtain the YouTube video titles, I built a simple data scrapper using the Python programming language and the YouTube Data API. From all the information available per video, I extracted only the video title and then saved the final list in a text file for each YouTube channel.
📈 Early Ideation
The natural next step was to start migrating to a web-development-friendly language. After translating to JavaScript and some console.log testing, I achieved a small web demo! Wait, you're telling me I can use anything as training data as long it's stored in a text file?
My current favourite artist is Taylor Swift, someone who needs no further introduction. To add my own twist to this project, I saved all of her lyrics from her albums reputation and onwards. Credits to Reddit user mountaingoatcheese for capturing all the lyrics on publicly accessible Google Docs. After tinkering around with regex, the generater could now handle punctuation marks and brackets.
In short, regular expression, or RegEx, is used to find text matching to a particular pattern. So far, I utlized regex when reading a text file. The regex will match to the pattern located inside a character class [...]:
- Split entire text to read by each line
- 1
var lines = text.split(/[\n\r]+/) - 2
for (var line of lines){...}
- 1
- Split each line at each white-space/empty character to obtain
Stringarray of individual events- 3
var split = line.split(/[\s]+/)
- 3
It was not uncommon for song lyrics to contain capital letters, paired typographical symbols (e.g. quotation marks, various brackets and parentheses), and other punctuation marks. I modified my regex to also split at these symbols/marks but retain them, such that they were recognized as a valid String event. As well, I changed the entire text to lowercase for simplicity:
- 1
var lines = text.toLowerCase().split(/[\n\r]+/) - 3
var split = line.split(/(?<=["(),.!])[\s]*|[\s]*(?=[ .,:;!?"()])+[\s]*/)
...
🔬 Testing
Testing primarily involved ensuring good performance (i.e. consistently generating results). Sometimes, results contained an incomplete set of brackets or quotation marks. And so, I added an extra step at the end to close or complete these leftover symbols.
About half the time, the generator produced results that made some sense and followed basic English grammar syntax. It was good enough, but there was massive room for improvement. And besides, I was not achieving consistent results like Johnson's site.
At first, I thought that I needed more data so it could "train" more. However, I realized that it did not matter because each event was only comprised of a valid one-String sequence. This definition of an event was too limited to produce anything with a high likelihood of making sense. I needed to somehow provide as much context as possible into each stored event.
⭐ Final Designs
Credits to this article by Alex Bespoyasov for helping me understand what "tokens" are. Essentially, what I built so far was utilizing one token: an event corresponded to one valid String. By increasing the number of tokens, this would help provide more context for the chain generator.
I added a constant global variable called NUM_TOKENS ∈ℕ. When NUM_TOKENS = n, one event corresponds to a valid n-String sequence. For example, let n = 2 and consider again: the quick brown fox jumps over the lazy dog
With this change in the definition of an event, a dictionary would look like this (event → next event):
- [START] →
the,quick the,quick→brownquick,brown→foxbrown,fox→jumpsfox,jumps→overjumps,over→theover,the→lazythe,lazy→doglazy,dog→ [END]
I decided to keep NUM_TOKENS = 2. For any value greater, the results were not random enough (i.e. too much context/not enough data) and we already know why 1 was subpar. Furthermore, I changed the way the program tracked the aforementioned incomplete symbols. Consequently, I was able to regex more paired typographical brackets (i.e. [], {}, <>).
Yes, I used regex as if it was a verb. Although these additional brackets were uncommon in lyrics, I added them and a few other symbols anyway. Here is what a few of the latest regex lines looked like:
- 3
var split = line.split(/(?<=["(){}<>[\],.!+=—])[\s]*|[\s]*(?=[ .,:;!?&+="()[\]{}<>—])+[\s]*/), retains every:- valid combo of letters
- punctuation mark
- typographical symbol
- hyphenated words
- words with apostrophe(s) or single quotation mark(s)
- first letter capitalization
- Check if the first character is a capital letter
.substring(0,1).match(/[A-Z]/)
- Track paired symbols
.match(/[()[\]{}<>"]/)
And so, the entire generating process looked like this:
- Load the correct text file(s)
- For each text file: split, read and record the valid events
- Append a random line starter
- Get and append each random proceeding event (while considering a few formatting rules)
- Deal with any incomplete symbols
- Capitalize the first character, if applicable
Additionally, I added functionality to track capitalization. The Node object now includes an additional boolean field that acts as a flag for to indicate if the event should have its first letter capitalized. The final result at the end will also always have its first letter capitalized.

Lastly, I finalized the HTML and CSS... and voila, I had my webpage fully designed! Check it out here!
❓ What I Learned
I achieved my initial goal of learning about Markov!
Additionally, I learned about regex lookbehind and lookahead, and practiced more with JavaScript and JQuery. These were extremely helpful when extending the functionalities of my generator.
For example, let's examine: 3var split = line.split(/(?<=["(){}<>[\],.!+=—])[\s]*|[\s]*(?=[ .,:;!?&+="()[\]{}<>—])+[\s]*/)
- Look behind positive
?<=: find any amount of white space characters[\s]*that is preceded by any of the symbols["(){}<>[\],.!+=—]- Splits the line after each of the symbols
- Look ahead positive
?=: find any amount of white space characters[\s]*that is followed by one or more of any of the characters[ .,:;!?&+="()[\]{}<>—]+that has any amount of white space characters[\s]*after them- Splits the line before each of the symbols
- Removes white space characters that may occur after any of the symbols
💭 Next Steps
This version is the base implementation I am satisfied and happy with!
Looking ahead (ha!), I would like to incorporate more English grammar rules and additional text syntax, like retaining full capitalization and managing any dots/periods for acronyms and abbreviations.